
 智东西
智东西
智东西9月15日报谈,今天,阿里巴巴通义履行室推出了FunAudio-ASR端到端语音识别大模子。这款模子通过篡改的Context模块,针对性优化了“幻觉”、“串语种”等要害问题,在高噪声的场景下,幻觉率从78.5%着落至10.7%,着落幅度接近70%。
FunAudio-ASR使用了数千万小时的音频数据,和会了大语言模子的语义相接武艺,从而晋升语音识别的高下文一致性与跨语言切换武艺。
通义履行室打造了5大类测试集,重心眷注语音识别在远场、嘈杂布景等挑战性场景下的施展,并联结开源测试集评估了模子的性能。FunAudio-ASR杀青了杰出Seed-ASR、KimiAudio-8B等业内知名模子的施展。

同期,FunAudio-ASR在内容落处所面也进行了全面优化,补助低蔓延流式识别、跨中英文当然切换以及用户可自界说的热词识别,随机隐敝视频会议、及时字幕、智能结尾等万般化应用场景。
FunAudio-ASR提供两个版块,满血版由0.7B参数目的编码器和7B参数目的大语言模子构成,追求最高精度;轻量的nano版块由0.2B参数目的编码器和0.6B参数目的大语言模子,均衡服从与精度。现在,FunAudio-ASR已在钉钉的“AI听记”、视频会议、DingTalk A1硬件等多个场景中应用。
FunAudio-ASR已上线阿里云百真金不怕火平台,API订价为0.00022元/秒,转录一段一小时的音频大要需要8毛钱。这款模子的时期答复还是发布,竖立者也可在魔搭社区体验其恶果。
魔搭社区体验:
https://modelscope.cn/studios/iic/FunAudio-ASR
阿里云百真金不怕火平台:
https://help.aliyun.com/zh/model-studio/recording-file-recognition?spm=a2c4g.11186623.help-menu-2400256.d_0_3_1.f43e7432ytYkAa&scm=20140722.H_2880903._.OR_help-T_cn~zh-V_1
时期答复:
https://github.com/FunAudioLLM/FunAudioLLM.github.io/blob/master/pdf/FunAudio-ASR.pdf
一、幻觉、串语种问题获针对性优化,一手体验高噪声环境识别恶果比较于文本大模子,语音大模子的“幻觉”问题尤为杰出。这是因为声学特征与文本特征在向量空间上自然存在各异,导致模子在“听”完音频后,容易“脑补”出大量不存在的内容。
尽管通过熟识,不错将将声学特征对皆到文本特征空间,但声学特征Embedding与实在的文本Embedding仍然存在这一定的差距,这会导致大语言模子在生成文本时发生幻觉的表象。
▲声学特征Embedding与实在的文本Embedding散布各异(图片着手:https://arxiv.org/pdf/2410.18908)
通义履行室发现,给语音大模提供必要的高下文,不错减少文本坐褥期间的幻觉表象。为此,他们谋划了Context增强模块:该模块通过CTC解码器快速生成第一遍解码文本,并将该律例算作高下文信息输入大语言模子,辅助其相接音频内容。
由于CTC结构轻量且为非自追思模子,险些不增多独特推理耗时。
举例,关于这段由AI生成、效法海盗言语作风的音频,FunAudio-ASR作念到了一字不差的识别。
(待插入)
此外,通义履行室还不雅察到幻觉问题在高噪声场景中更易发生,因此在熟识数据中加入了大量仿真数据。
为评估模子在高噪声情况下的施展,他们构建了一个包含28条易触发幻觉音频的测试集,经优化后,幻觉率从78.5%着落至10.7%。
智东西在实测中体验了FunAudio-ASR在嘈杂场景的识别武艺。这段音频是在嘈杂的展会现场录制的。不错听到,模子基本准确识别了片断中男性言语者的声息,但在声息音量骤降后识别造作了。
(待插入)
同期,这段音频中有两位言语者,FunAudio-ASR在识别两东谈主同期言语的部分时,遗漏了一些信息。
与OpenAI Whisper Large V3的识别律例对比,FunAudio-ASR识别出了更多正确的信息。

“串语种”是语音大模子落地中的另一类典型问题,举例,输入音频内容为英文,模子输出却为华文文本。
这是因为文本大模子自身具备翻译武艺,在声学特征映射不够精确时,模子可能在推理进程中“自动启动”翻译功能,从而影响语音识别的准确性。
在FunAudio-ASR的Context增强模块中,CTC解码器经过高质地数据熟识,自身发生串语种的概率极低。通过将CTC的第一遍解码律例算作提醒词输入给大语言模子,可有用携带模子聚焦于语音识别任务,缓解“翻译”行径的发生。
二、补助术语定制化识别,调回率晋升彰着在企业驾驭语音识别模子时,个性化定制是必不成少的时期。所谓定制化,是指在识别进程中对特定词/短语(如东谈主名、地名、品牌、专科术语等)施加独特概率偏好,从而权臣提高它们的识别调回率,同期尽量不挫伤通用识别准确率。
刻下行业的主流作念法是将用户提供的领域词,胜仗算作提醒词输入大语言模子。该圭臬虽简便有用,但跟着词量增多,干豫也随之上涨,导致调回率着落——即“定制化武艺衰减”。
为缓解这一问题,通义履行室在Context增强结构中引入RAG(检索增强生成)机制,这一机制的运作阵势如下:
(1)构建学问库:将用户树立的定制词构建成专属RAG库;
(2)动态检索:依据CTC第一遍解码律例,从RAG库中抽取但是汇;
(3)精确注入:仅将但是集合入大语言模子的提醒词中,幸免无关信息干豫。
该决策在不增多推理复杂度的前提下,将定制化上文数目引申到上千个以上,何况保抓较高的定制化识别恶果。
为考据模子的定制化恶果,通义履行室在微积分学、有机化学、物理学、玄学、东谈主名等5个领域,及第了1000个专科词汇进行测试。FunAudio-ASR在要害词准确率上施展杰出了补助同类功能的语音识别模子。
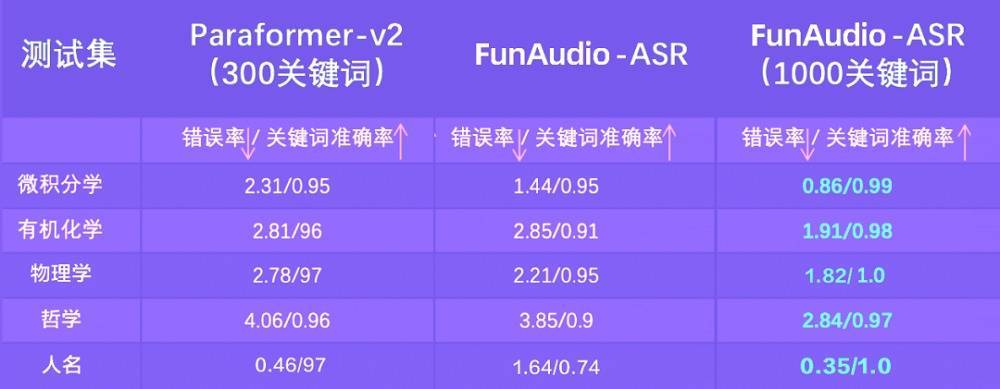
举例,罗致FunAudio-ASR模子的钉钉“AI听记”,领有对互联网、科技、家装、畜牧、汽车等10+领域、200+细分行业术语的识别武艺,并补助在企业授权前提下,联结通信录、日程等高下文信息进行推理优化,进一步晋升律例可靠性。
时期答复中,通义履行室陈诉了FunAudio-ASR的时期细节。这一模子包含四个中枢组件:
(1)音频编码器(Audio Encoder):提真金不怕火语音特征,使用多层Transformer Encoder。
(2)音频适配器(Audio Adaptor):联接编码器和LLM,使用两层Transformer Encoder。
(3)CTC解码器:用于初步识别假定,补助热词定制。
(4)基于大语言模子的解码器:联结音频特征和CTC展望生成最终输出。

▲FunAudio-ASR模子架构
预熟识阶段,FunAudio-ASR使用了数千万小时的音频数据,包括无标注音频和有标注的音频-文本数据,数据涵盖AI、生物、电商、教练等多个领域。
预熟识分为自监督预熟识和有监督预熟识。在自监督阶段,FunAudio-ASR篡改地使用Qwen3的权重运行化编码器,加快拘谨并晋升示意质地。
有监督预熟识则在编码器-解码器架构(AED)下进行,使编码器随机从大鸿沟标注数据中学习更丰富的声学-语言特征,为后续与大语言模子的整合奠定基础。

▲FunAudio-ASR预熟识管线
在此基础上,FunAudio-ASR干涉有监督微调(SFT)阶段,该阶段进一步分为五个子阶段,逐步优化不同模块:
(1)熟识适配器以对皆音频示意与大语言模子的语义空间;
(2)优化编码器和适配器;
(3)使用LoRA微调大语言模子以退守烦恼奋性渐忘;
(4)全参数微调阶段;
(5)引入CTC解码器用于后续的热词检索与增强生成(RAG)。
扫数SFT进程使用了数百万小时的多源数据,包括东谈主工标注语料、伪标注数据、合谚语音和噪声增强数据等,确保了模子在万般化场景下的泛化武艺。
为了进一步晋升模子对长音频和高下文信息的相接武艺,团队还构建了跨越5万小时的高下文增强熟识数据。
通过提真金不怕火要害词、合成关联高下文并羼杂无关语境,模子学会了在保抓高识别精度的同期,有用利用对话历史信息,权臣晋升了在复杂语境下的施展。
在强化学习(RL)阶段,团队提倡了专为音频-语言模子谋划的FunRL框架,补助多模块高效协同熟识。

▲FunRL框架
该框架罗致GRPO算法,并谋划了多指标奖励函数,详尽优化识别准确率、要害词调回、幻觉扼制和语言一致性。模子仅使用8张A100显卡,在一天内完成RL熟识。
RL熟识数据涵盖硬样本、长音频、幻觉样本、要害词样本和惯例ASR数据,权臣晋升了模子在费劲场景下的鲁棒性和用户体验。
终末,FunAudio-ASR还针对内容应用需求进行了全面优化,包括流式识别补助、噪声鲁棒性增强、中英代码切换搞定、热词定制和幻觉扼制等。
结语:生成式AI赋能新一代ASR系统,或成智能交互进攻进口基于生成式AI的新一代语音识别模子,正在从“能听清”走向“能相接”,并在幻觉扼制、跨语种识别、高下文一致性等要害问题上展现出进展。
与传统以声学建模与统计学习为主的语音识别系统比较开云「中国」集团Kaiyun·官方网站开云体育,这类模子不仅具备更强的语义相接与任务适配武艺,还能在复杂噪声、多言语东谈主、跨领域等场景中保抓更高的鲁棒性和可控性。不错料念念,昔时语音识别有望告别单纯的“输入器具”,成为结尾智能交互的进攻进口。